This post is 2nd part of 3-post series. In the earlier post, we understood the fundamentals of BigQuery Load Jobs Export & Load Job with MongoDB - BigQuery Part-I. In this post, we are going to dive into Streaming feature of BigQuery.
Streaming
Why ? - Streaming helps in pushing our data into BigQuery (short for BQ) and helps in making data available for query without delay of running load jobs.
There are some trade-offs to choose Streaming. A few are belows :
- We need to follow a few quotas like http body size, maximum rows / request etc while making streaming API calls.
- Written data in tables are not instantly available for copy or for export jobs in bigquery, it will take upto 90 minutes to be made available while load based tables are available instantly.
- At the time of writing this post, charges incurred in streaming whereas load jobs were free.
Keeping above in mind, we need to choose streaming vs load jobs in BigQuery.
Quotas : https://cloud.google.com/bigquery/quotas#streaminginserts
Streaming Data into BigQuery
In this article, we are going to use a redis server as a message broker to hold our data.
We are going to prepare data and the skeleton of data is going to be basic information of any person (username, name, birthdate, sex, address, email). As per this information, we need schema and table in bigquery to be created in advance before streaming. Post table creation, we are going to run streaming program to ingest our data in bulk which will be read from redis and same will be written to bigquery table in real time.
We are going to use python as our programming language.
1. Prepare data in Redis

We are going to write a small python script to preapare data in redis List.
Redis Installation : https://redis.io/download
If you have docker running, run redis inside container with simple command
docker run -d --name redis-streaming -p 6379:6379 redis
Script is going to execute LPUSH command in redis to insert data into list named as redisList . With the help of Faker library we are going to generate some fake profile as our data.
Faker : https://github.com/joke2k/faker
#!/usr/bin/env python
import redis
import json, time
#Faker : https://github.com/joke2k/faker
from faker import Faker
streamRedis = redis.Redis(host='127.0.0.1',
port='6379',
password='')
fake = Faker()
def profile_generator():
return fake.simple_profile(sex=None)
def main():
while True:
streamRedis.lpush("redisList", json.dumps(profile_generator()) )
#sleep 200ms
time.sleep(0.2)
if __name__ == "__main__":
main()
2. Inspect data and prepare schema for Table
Our data looks like :
{
'username': u'tarawade',
'name': u'Jennifer Lewis',
'birthdate': '2005-06-14',
'sex': 'F',
'address': u'7134 Robinson Club Apt. 530\nPort Andreachester, GA 19011-6162',
'mail': u'tmorgan@yahoo.com'
}
For the above formatted data, below schema is going to work :
[
{
"name": "username", "type": "STRING", "mode": "NULLABLE"
},
{
"name": "name", "type": "STRING", "mode": "NULLABLE"
},
{
"name": "birthdate", "type": "STRING", "mode": "NULLABLE"
},
{
"name": "sex", "type": "STRING", "mode": "NULLABLE"
},
{
"name": "address", "type": "STRING", "mode": "NULLABLE"
},
{
"name": "mail", "type": "STRING", "mode": "NULLABLE"
}
]
3. Create a table in BigQuery
We are going to create two python file, ie, createConfig.py that will keep schema configuration and tableCreate.py that will execute the table creation API call to bigquery. We are going to use Google Application Default Credentials to authorize our python application to talk to bigquery APIs.
$ cat createConfig.py
TableObject = {
"tableReference": {
"projectId": "mimetic-slate",
"tableId": "StreamTable",
"datasetId": "BQ_Dataset",
},
"schema": {
"fields": [
{
"name": "username",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "name",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "birthdate",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "sex",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "address",
"type": "STRING",
"mode": "NULLABLE"
},
{
"name": "mail",
"type": "STRING",
"mode": "NULLABLE"
}
],
},
}
We are going to use ** google-api-python-client** library for interacting to our bigquery APIs.
We are building service object by calling our API name and version supported by API. In this case we are using bigquery with version v2. This service object will be used to make tables related operation. As of now we are going to use insert function to make table.
GoogleCredentials.get_application_default() will read the credentials stored in my system. Either you need to export a variable mentioned in reference with service account key or you setup an google SDK which will store default credentials inside your home directory.
ls ~/.config/gcloud/*.json
~/.config/gcloud/application_default_credentials.json
#!/usr/bin/env python
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
from tableCreate import TableObject
def createTable(bigquery):
tables = bigquery.tables()
#insert utility make call to BQ API with payload \
#(TableObject) contains schema and table-name information
tableStatusObject = tables.insert( projectId='mimetic-slate', \
datasetId='BQ_Dataset', body=TableObject).execute()
# [END]
def main():
#to get credentials from my laptop
credentials = GoogleCredentials.get_application_default()
# Construct the service object for interacting with the BigQuery API.
bigquery = discovery.build('bigquery', 'v2', credentials=credentials)
createTable(bigquery)
if __name__ == '__main__':
main()
print "BQ Table Creator !!"
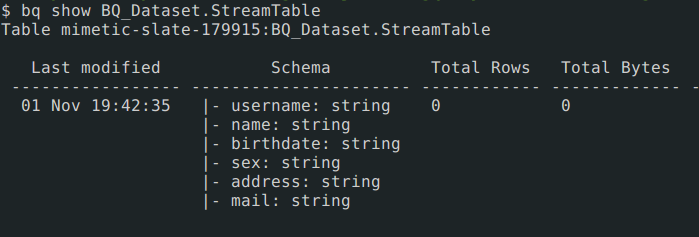
Run above to program to create table with name StreamTable in bigquery dataset BQ_Dataset. Make sure you have created dataset already.
You can verify the table created by visiting bigquery UI. Visit : https://bigquery.cloud.google.com
You can also verify table creation by running bq CLI commands
$ bq ls BQ_Dataset
tableId Type Labels Time Partitioning
------------- ------- -------- -------------------
StreamTable TABLE
**Reference ** :
-
**Table Creation : ** https://developers.google.com/resources/api-libraries/documentation/bigquery/v2/python/latest/bigquery_v2.tables.html
-
Google Application Default Credentials : https://developers.google.com/identity/protocols/application-default-credentials
-
Build the service object : https://developers.google.com/api-client-library/python/start/get_started#build-the-service-object
4. Streaming into Bigquery
Now, we have table created and data queued into redis list, We are ready to stream right away by running a python script, lets call this script bq-streamer.py
#!/usr/bin/env python
from googleapiclient import discovery
from oauth2client.client import GoogleCredentials
import json, time, copy
import redis
batchCount = 100
redisStream = redis.Redis(host='127.0.0.1',
port='6379',
password='')
streamObject = {
"rows": [
#{ "json": {# Represents a single JSON object. } }
],
}
#[START Streaming batcher]
def streamBuilder():
#Every API needs a refresh copy of dict
newStreamObject = copy.deepcopy(streamObject)
currentCounter = 0
while currentCounter < batchCount:
packet = redisStream.brpop("redisList", timeout=0)[1]
newStreamObject["rows"].append({"json" : json.loads(packet) })
currentCounter += 1
return newStreamObject
#[END]
# [START Streaming Utility]
def streamUtils(bigquery):
tabledata = bigquery.tabledata()
#Run infinitely
while True:
streamBuildBatch = streamBuilder()
#BQ API to insert bulk data into table
insertStatusObject = tabledata.insertAll(projectId='mimetic-slate', \
datasetId='BQ_Dataset', tableId='StreamTable', \
body=streamBuildBatch).execute()
# [ MAIN]
def main():
credentials = GoogleCredentials.get_application_default()
# Construct the service object for interacting with the BigQuery API.
bigquery = discovery.build('bigquery', 'v2', credentials=credentials)
#Stream utility
streamUtils(bigquery)
# [END]
if __name__ == '__main__':
main()
Above program is going to read redis running on 127.0.0.1:6379 from list name redisList and build a dict object streamObject that is accepted by bq streaming API. We are calling insertAll utility to submit our streaming request to bigquery API.
insertAll takes projectId, datasetId, tableId as an argument and body which contains your data to be streamed.
Script has been configured to pop 100 entries from redis list and prepare it to be pushed into table. Run bq-streamer.py script to start streaming data into bigquery table.
#when bulk data is prepared, JSON payload in body argument would look like
{
"rows": [
{
"json": {
"username": "nicholaswagner",
"name": "Laura Scott",
"birthdate": "1970-11-30",
"sex": "F",
"address": "788 Faulkner Locks Suite 687\nSanfordside, FL 50804-6818",
"mail": "austinnathaniel@yahoo.com"
}
},
{
"json": {
"username": "david27",
"name": "Aaron Silva",
"birthdate": "2003-09-17",
"sex": "M",
"address": "57976 Collins Loaf Apt. 843\nMichaelfort, VA 79233",
"mail": "dbeck@hotmail.com"
}
},
.....
more data
.....
}
Reference :
- Streaming insertAll : https://developers.google.com/resources/api-libraries/documentation/bigquery/v2/python/latest/bigquery_v2.tabledata.html
5. Verify the data in BigQuery Table
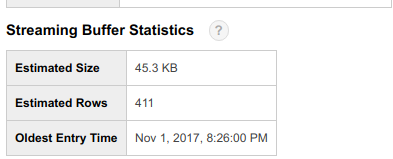
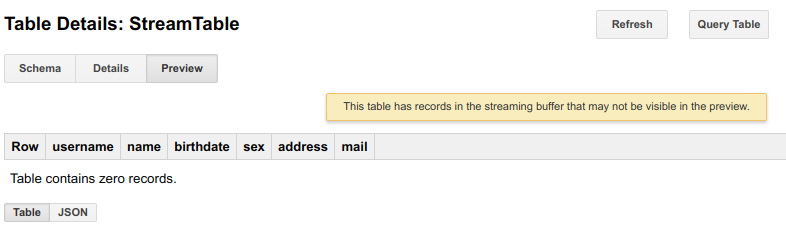
After running streaming, you will start seeing something similar as shown below when you click table info. Clicking on preview will not show you any streamed data, it will take a while to appear but it will be in buffer to be available for query instantly.
SQL Query in BQ Table
We are going to run a simple query to show the output that shows your streamed data.
SELECT * FROM [mimetic-slate:BQ_Dataset.StreamTable]
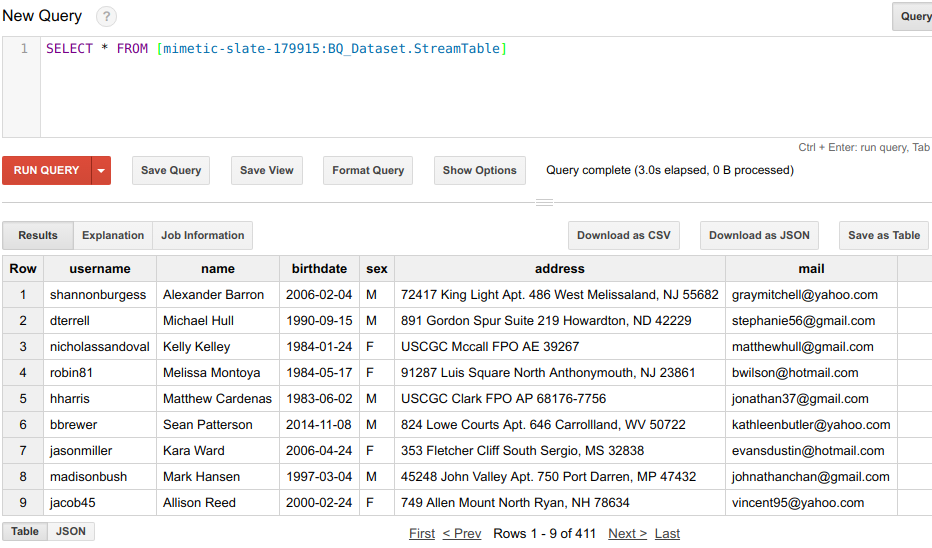
Github reference : https://github.com/sunnykrGupta/Bigquery-series
Conclusion
That's all from this series Part-II. Hope you will get basic understanding of Streaming in BigQuery from this post. Streaming is helpful in cases when you want your data to be instantly available for query, helps in scenario where have a requirement of building real time analysis.
I would appreciate feedback via comments. In next blog which is part of this series, I will be covering Patching and Updating table schema in Bigquery which is important when you want to add fields in table.